This is continuation of previous post https://eikonal.wordpress.com/2010/02/17/some-examples-of-the-moore-penrose-inverse/
Example (added 2010.02.25 Fri): 








To find the MPI of that matrix, start with the transposed matrix 

,
.
Now calculate 




 .
.
Direct check verifies that all four defining properties of MPI are satisfied.
Note that 

The two products 





More at this blog:
- Some examples of the Moore-Penrose inverse – https://eikonal.wordpress.com/2010/02/17/some-examples-of-the-moore-penrose-inverse/
- Weighted Moore-Penrose inverse – https://eikonal.wordpress.com/2010/02/19/weighted-moore-penrose-inverse/
 of a matrix
of a matrix  is defined by the following four properties:
is defined by the following four properties: ,
, ,
, ,
, .
. and
and  are of the orders
are of the orders 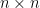 and
and  .
.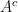 .
.  (called the Moore-Penrose inverse [MPI]) s/t:
(called the Moore-Penrose inverse [MPI]) s/t: ,
, ,
, ,
, .
. is the appropriate conjugation defined on the field
is the appropriate conjugation defined on the field  , i.e.
, i.e.  (
( ).
).  :
: ,
, ,
, is the transposition of the matrix
is the transposition of the matrix  .
. :
: ,
, ,
, is the Hermitian conjugation of a matrix
is the Hermitian conjugation of a matrix  has infinitely many solutions
has infinitely many solutions
 is satisfied.
is satisfied.
 is a square positive semidefinite matrix, then for each
is a square positive semidefinite matrix, then for each  the following inequality holds:
the following inequality holds: .
. .
.![\underline{z}=(A^T B A)^{+} A^T B \underline{x} + [{\bf 1}_n - (A^T B A)^{+}(A^T B A)]\underline{q}](https://s0.wp.com/latex.php?latex=%5Cunderline%7Bz%7D%3D%28A%5ET+B+A%29%5E%7B%2B%7D+A%5ET+B+%5Cunderline%7Bx%7D+%2B+%5B%7B%5Cbf+1%7D_n+-+%28A%5ET+B+A%29%5E%7B%2B%7D%28A%5ET+B+A%29%5D%5Cunderline%7Bq%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.  and
and  are projectors:
are projectors:  .
.
 .
.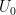 by dropping the empty rows (getting
by dropping the empty rows (getting  ), and trim
), and trim 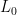 by trimming the corresponding columns (getting
by trimming the corresponding columns (getting  ). Note that it is still valid that
). Note that it is still valid that  .
.
 and
and  , to get
, to get  .
. ,
, ,
, ,
, .
. ,
, ,
, ,
, .
. ,
, ,
, ,
, .
. ,
, , where
, where  ,
, ,
, .
.